Deep-archive an aws S3 bucket with versioning enabled once
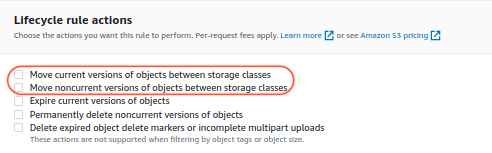
It's not a surprise if you want to deep-achieve a S3 bucket, or some objects in it to decrease storage cost. But if versioning has once been enabled on the bucket, how to do the deep archiving needs more consideration. Problem Statement If you have a S3 bucket, which versioning has never been enabled, then to move objects into Glacier Deep Archive can be achieved by iterating over every object, and making a copy of an object using the PUT Object - Copy API. You copy an object in the same bucket using the same key name and specify request headers, e.g. here you set the x-amz-storage-class to the storage class, ' DEEP_ARCHIVE', that you want to use [1]. Then the final effect is just like that the storage class of an object is being changed. But if a bucket has once been versioning enabled, the above method is not straight forward. - If versioning is still enabled, even you can copy an object with a spec...
