Deep-archive an aws S3 bucket with versioning enabled once
It's not a surprise if you want to deep-achieve a S3 bucket, or some objects in it to decrease storage cost. But if versioning has once been enabled on the bucket, how to do the deep archiving needs more consideration.
Problem Statement
If you have a S3 bucket, which versioning has never been enabled, then to move objects into Glacier Deep Archive can be achieved by iterating over every object, and making a copy of an object using the PUT Object - Copy API. You copy an object in the same bucket using the same key name and specify request headers, e.g. here you set the x-amz-storage-class to the storage class, 'DEEP_ARCHIVE', that you want to use [1]. Then the final effect is just like that the storage class of an object is being changed.
But if a bucket has once been versioning enabled, the above method is not straight forward.
- If versioning is still enabled, even you can copy an object with a specific version ID, Amazon S3 gives it a new version ID. Then you need to delete the old version ID, otherwise you will double the cost instead of decreasing cost. The whole procedure turns verbose.
- If versioning is suspended, when an object with a specific version ID is copied, the version ID that Amazon S3 generates is always null. So if an object has multiple versions before deep archiving, this method will overwrite previously copied versions.
So we'd better look for a simpler and more reliable way to do the deep archiving.
Solution
S3 lifecycle rule can help on it. There are two rule actions as marked in red below, which can move current versions, and non-current versions respectively to a specified storage class.
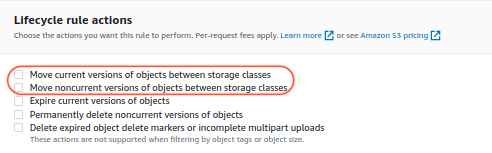
So you can create a rule to use those two actions, and set the waiting days before the transition to 1 day, which is shortest days you can set. As shown below, you can also filter objects by prefix, object tags, object size, or whatever combination suits your use case.

Note there might be a delay between when the lifecycle rule is satisfied and when the action for the rule is complete. Additionally, Amazon S3 rounds the transition or expiration date of an object to midnight UTC the next day.[2]
Further Reading
S3 lifecycle rule evaluates the days elapsed after object creation, or after objects become non-current. There is no out-of-box rule to take actions based on object access time instead of creating time. A rule based on object access time makes more sense in some cases, in order for less accessed objects to be deep-archived earlier. If this is your use case, you may have the interest to read this blog, Expiring Amazon S3 Objects Based on Last Accessed Date to Decrease Costs
Comments
Post a Comment